
ChatGPT는 Gen AI 중 하나로, 2022년 11월 30일에 발표된 GPT를 챗봇 형태로 Fine-Tunung한 언어 모델을 말한다!
이 때, GPT는 OpenAI에서 만든 초거대 언어 모델로, 일반적인 내용을 바탕으로 훈련된 파운데이션 모델을 의미한다.
현재 GPT 4 Turbo 버전까지 나왔으며, ChatGPT 4.0 역시 등장하였다.
ChatGPT 3과 달리 ChatGPT 4에서는 언어지원 개선, 8배 더 큰 단어 컨텍스트 지원, 코딩 인터프리터 지원 등의 엄청난 기능이 추가되었다. 첨부파일을 제공하여 다양한 기능을 수행할 수도 있다!
Gen AI와 GPT, ChatGPT 등에 관련된 설명은 아래 글에 자세히 작성해두었다.
2024.02.22 - [STUDY/DevCourse] - [데브코스][데이터 분석] Gen AI를 이용한 생산성 증대
[데브코스][데이터 분석] Gen AI를 이용한 생산성 증대
< 2주차 데이터 분석 소개(5) > 4-1. 퀴즈 리뷰 생략 4-2. Gen AI란? _ 첫번째 인공지능, 머신러닝, 딥러닝 - 인공지능 : 인간이 하는 일을 대신 해주는 시스템을 만드는 컴퓨터 과학 - 머신러닝 : 인공지
yeonnys.tistory.com
ChatGPT 4.0의 Code Interpreter 기능을 사용하면 쉽게 csv 파일을 첨부하여 데이터 분석을 요청할 수 있다.
그러나 ChatGPT 4.0의 경우 한 달에 2만원이 넘는 금액을 내야하는 유료 버전이기에 (ㅠㅠ)
우리는 무료로 사용할 수 있는 ChatGPT 3.5로 데이터 분석을 해보고자 한다!
우리가 분석할 데이터는 캐글에서 제공해 준 데이터로, 데이터 설명부터 GPT에게 요청해보겠다!
: Gapminder 데이터 -> 나라별 특정 연도에 인구가 몇 명인지, 어떤 종인지, 평균수명, GDP 등을 나타내는 데이터이다.
https://www.kaggle.com/datasets/tklimonova/gapminder-datacamp-2007
Gapminder World
Dataset from Gapminder World website from 1952 to 2007.
www.kaggle.com

ChatGPT에 질문을 할 때에는 ChatGPT가 어떤 역할을 할 것인지 등
1) 역할 부여 / 2) 해야할 일 설명 / 3) Format 제공 / 4) 방향성 / 5) 필수사항 + 제한사항
과 같은 사항들을 언급해주는 것이 중요하다.


이런식으로 어떤 분석을 해볼 수 있는지에 대한 정보를 얻었다.

ChatGPT 4 버전에서는 이미지를 표현해줄 수 있지만, 우리가 사용하는 무료버전에서는 불가능하므로 파이썬 코드를 요청하여 직접 그래프를 그려보자!

(ChatGPT가 제공해 준 코드)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
data = pd.read_csv("gapminder_data.csv")
# 상관 행렬 생성
correlation_matrix = data.corr()
# 평균수명과의 상관 관계만 추출
life_expectancy_correlation = correlation_matrix['life_expectancy'].drop('life_expectancy')
# 상관 관계의 절대값 기준으로 내림차순 정렬
life_expectancy_correlation = life_expectancy_correlation.abs().sort_values(ascending=False)
# 상위 상관 관계를 가진 변수 출력
print("평균수명과의 상관 관계가 가장 큰 변수:\n", life_expectancy_correlation.head(1))

# 가장 큰 상관 관계를 가진 변수와의 관계 시각화
top_correlation_variable = life_expectancy_correlation.index[0]
sns.scatterplot(data=top_correlation_variable, x='life_expectancy', y=top_correlation_variable)
plt.xlabel("평균수명")
plt.ylabel(top_correlation_variable)
plt.title("평균수명과 " + top_correlation_variable + "의 관계")
plt.show()

이제, 위에서 제공해 준 코드를 파이썬으로 직접 실행해보자
데이터는 위의 사이트에서도 다운로드할 수 있고, 편의를 위해 CSV 파일을 첨부하겠다.
위의 코드를 실행하면,

이러한 에러가 발생한다.
에러를 해결해달라고 요청해보겠다.

--> 수치형 데이터가 아닌 데이터는 상관관계 분석이 불가능한데, 이를 신경쓰지 않고 모든 필드를 대상으로 상관관계 분석을 해서 생긴 오류이다.
ChatGPT가 수정하여 제공해준 코드를 바탕으로 파이썬 실행 결과... (굉장히 여러 번의 수정을 거쳤다. )
아래와 같다.
##### 실제로 실행된 코드
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
data = pd.read_csv("C://Users/user/Downloads/archive/gapminder_full.csv")
# 수치형 변수만을 선택
numerical_data = data.select_dtypes(include=['float64', 'int64'])
# 상관 행렬 생성
correlation_matrix = numerical_data.corr()
# 평균수명과의 상관 관계만 추출
life_expectancy_correlation = correlation_matrix['life_exp'].drop('life_exp')
# 상관 관계의 절대값 기준으로 내림차순 정렬
life_expectancy_correlation = life_expectancy_correlation.abs().sort_values(ascending=False)
# 상위 상관 관계를 가진 변수 출력
print("평균수명과의 상관 관계가 가장 큰 변수:\n", life_expectancy_correlation.head(1))
# 가장 큰 상관 관계를 가진 변수와의 관계 시각화
top_correlation_variable = life_expectancy_correlation.index[0]
sns.scatterplot(data=data, x=top_correlation_variable, y='life_exp')
plt.xlabel(top_correlation_variable)
plt.ylabel("평균수명")
plt.title(top_correlation_variable + "과 평균수명의 관계")
plt.show()
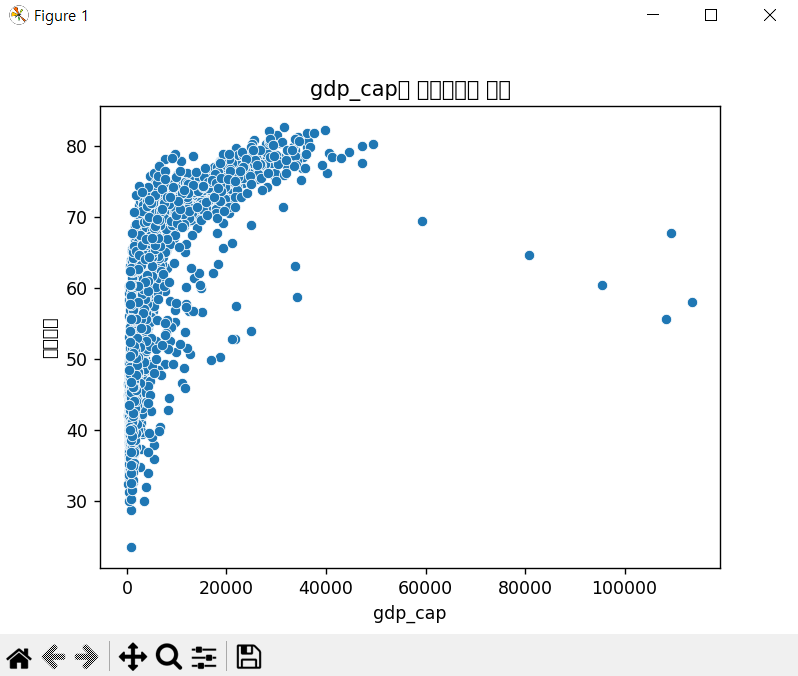

--> 결과를 보면, ChatGPT가 제공해준 코드 알고리즘 자체에는 문제가 없다.
그러나..
1) 파일 경로 -> 이는 쉽게 해결 가능
2) 필드명 확인!!!!!!!!! -> 이 과정에서 애를 먹었다.
3) 필드 분석이 상세히되지 않음 (문자형 변수인지, 수치형 변수인지.. ) -> 이 역시 반복되는 질문을 통해 해결 가능
====> 이러한 문제점들이 있다.
따라서 ChatGPT에게 부탁을 할 때에는 사소한 부분들을 잘 확인하는 것이 매우 중요하다.
개발에서 가장 중요한 부분은 "코드를 수정하는 과정"이기 때문이다!
주어진 데이터셋에 대한 자세한 설명도 요청해보았다!


무료버전이지만 꽤 자세하고 확실하게 데이터분석을 수행해주는 것을 확인할 수 있었다.
ChatGPT는 정말 대단한 존재이다.
잘 알고 잘 활용해보도록 하자!
'기타' 카테고리의 다른 글
| MAC 아나콘다 완전 삭제 및 설치 (2024년 3월 27일 기준) (0) | 2024.03.27 |
|---|---|
| 맥북 개발자 초기 환경설정하기 (2) (0) | 2024.03.04 |
| 맥북 개발자 초기 환경설정하기 (0) | 2024.03.04 |
| [NOTION] 노션 디데이 속성 추가하기(날짜 지남/오늘/~일 전) (1) | 2023.12.12 |
| 파이참(Pycharm) 버전 업데이트 및 설치 방법 (0) | 2023.11.04 |