
A/B 테스트 시스템 구성
: A/B 테스트 = 런타임 시스템 + 분석 시스템
런타임 시스템 : 사용자를 A에 둘지, B에 둘지 결정 (버킷 결정, 보통 백엔드 엔지니어+데이터 분석가가 진행)
-> A/B 테스트를 진행할 사용자 버킷 정보를 ETL을 통해 데이터 웨어하우스에 불러옴 (사용자별 행동, 이벤트 로그, 구매정보 등)
-> 분석 시스템 : dbt 등을 통해 분석하기 좋은 테이블로 만들고, 시각화 등 진행
A/B 테스트 구현 방법
- 직접 구현
- SaaS 사용 (Optimizely, VWO 등, 이들은 대부분 front-end 관련 테스트를 하는데 유용함)
-> 보통은 SaaS를 쓰다가 직접 구현하는 식으로 고도화됨
A/B 테스트 전체 과정
- A/B 테스트 제안 (주간미팅)
-> A/B 테스트 실행 & QA
-> Rollout
-> 반복 (주간리뷰, 대시보드 생성, 애자일한 방식 사용(속도 중요)
애자일한 A/B 테스트 시스템 과정
: 알고리즘 생성 -> 배포 -> A/B 테스트 setup -> A/B 테스트 분석 -> 개선
A/B 테스트 트래픽 나누기
: A/B 테스트 런타임 시스템의 기본은 트래픽을 A와 B로 나누는 것이다.
userid VS deviceid
- userid : 로그인한 사용자에게만 하는 테스트일 때 사용, 사용자 등록이 되는 순간 부여되는 유일한 ID
- deviceid : 모든 방문자에게 하는 테스트일 때 사용, 서비스 방문자에게 부여되는 ID로 보통 브라우저 쿠키를 이용해 만들어짐.
=> A/B 테스트의 성격에 따라 userid를 사용할지, deviceid를 사용할지 결정
사용자 미리 나누기 VS 동적으로 나누기
- 미리 모든 사용자를 A/B로 나누기
: 로그인한 사용자를 대상으로 하는 경우
: A/B 테스트 중 신규등록된 사용자에게 적용 불가능
그러나 다수의 A/B 테스트가 동시에 진행될 때, 상호작용을 최소화하는 방향으로 보장할 수 있음 (넷플릭스)
- 사용자를 동적으로 A/B 테스트 진행 중에 나누기
: 일반적으로 사용되는 방법
: 로그인한 사용자이건 아니건 적용, 앞의 방법보다는 bias가 생길 가능성이 있음
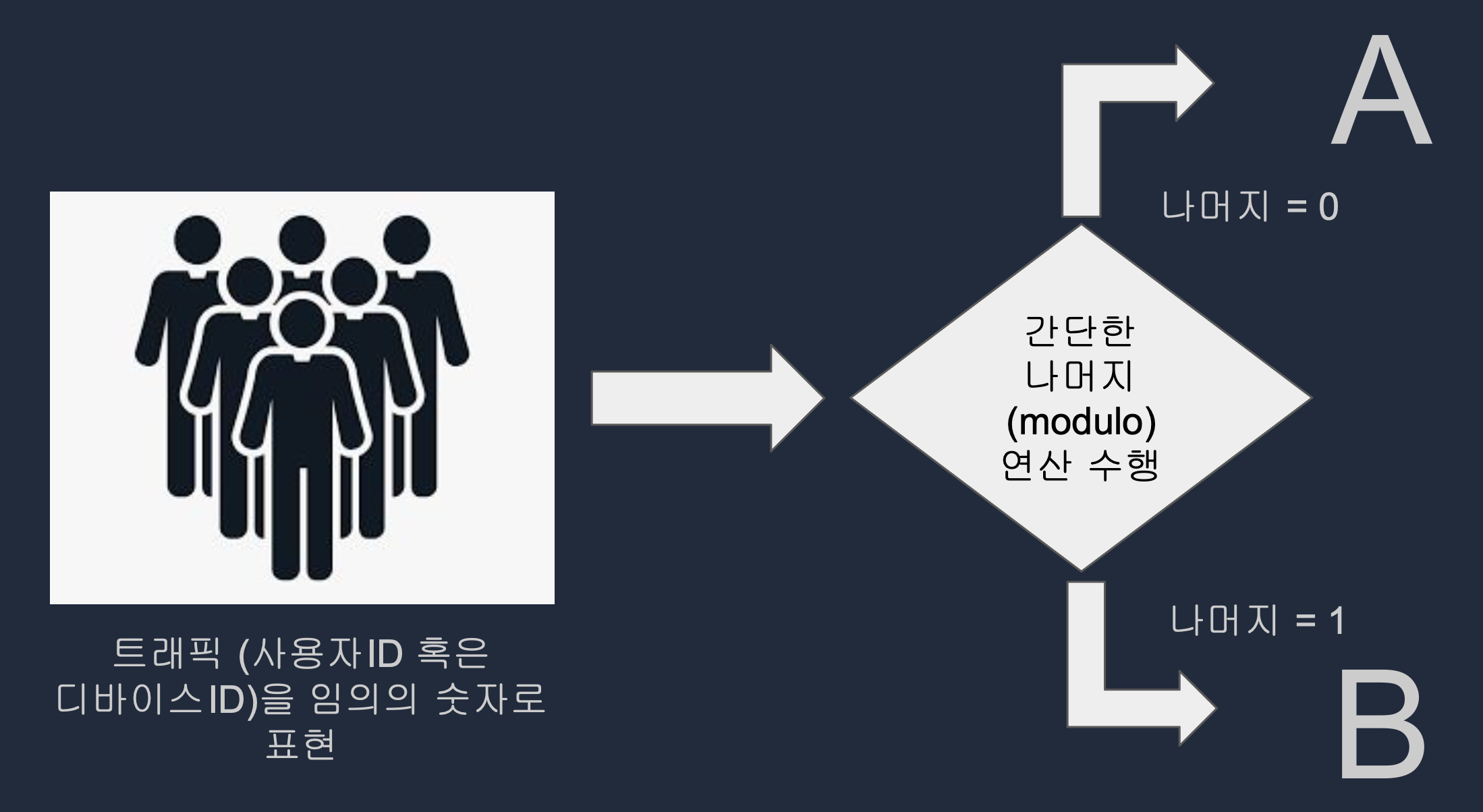
트래픽 나누기 로직
1. User ID 혹은 Device ID를 랜덤한 값으로 변경 (보통 MD5 사용)
2. MD5로 바뀐 값(16진수)을 숫자(10진수)로 변경
3. 앞서 나온 값에 Variant의 수(보통 A와 B 2개)로 나머지 연산(modulo) 수행
4. 앞서 나온 결과 값이 0이면 A, 1이면 B
# 파이썬
import hashlib
def split_userid(id):
"""Given an id and the number of variants, returns a bucket number"""
h = hashlib.md5(str(id).encode())
return int(h.hexdigest(), 16) % 2 # num_of_variants
-- SQL
SELECT
user_id,
MOD(STRTOL(LEFT(MD5(user_id),15), 16), 2) variant_id
FROM aa_example
-- LEFT는 오버플로우를 막기 위해 사용
-- STRTOL는 십육진수 문자열을 숫자로 바꾸기 위해 사용
-- MOD는 나머지 계산으로 값을 최종적으로 0과 1로 바꾸기 위해 사용
A/B 테스트 분석
- A/B 테스트의 결과 분석은 가설을 잘 세워야 배우는 것이 있음
=> 경험이 매우 중요함!
- 결과 분석은 객관적이고 공개되어야함
그렇지 않으면 몇 개인에 의해 이상한 결정이 될 수 있음
-> 다양한 사람들이 모인 자리에서 결과를 분석하고 여러 의견을 듣는 것이 좋음
outlier가 A/B 테스트에 미치는 영향
- 어느 서비스나 매출 등에 있어서 매우 큰 소비를 하는 고객이 존재함
-> 이들이 어느 버킷에 들어가느냐가 분석에 큰 영향을 미침 (이런 사람들은 무조건 구매를 하기 때문)
-> 평균 등에서 크게 벗어나는 이상치 값들은 A/B 테스트에서 제거할 필요가 있음
- 봇 유저(scrapping)가 한쪽으로 몰리는 경우
: 서비스의 40~50%의 트래픽은 봇 프래픽일 수 있음.
==> 항상 A/B 테스트 결과는 다양한 관점에서 바라봐야함
잘못된 가설
- survivorship bias
ex. 컴플레인 전화를 하는 사람들의 이탈율을 어떻게 높일까?
-> 그러나, 컴플레인 전화를 하는 사람들은 오히려 이탈율이 높지 않았음 -> 잘못된 가설 설정
시각화
=> AB 테스트 전체 기간에 걸쳐 중요한 지표가 비교 가능해야 한다.
-> 날짜별로 중요 지표가 어떻게 변화하는지 비교해야하며, 이것이 통계적으로 유의미한지 판단해야함.
또한, 사용자 메타 데이터에 따라 필터링이 가능해야함.
<실제 현업에서 A/B 테스트 과정>
1. A/B 테스트 시스템 구축
2. A/A 테스트를 통해 시스템 검증
3. 수십번의 A/B 테스트를 통해 ML 기반 추천 엔진 론칭
'STUDY > DevCourse' 카테고리의 다른 글
| [데브코스][데이터 분석] 애자일 A/B 테스트 (0) | 2024.05.20 |
|---|---|
| [데브코스][데이터 분석] 추천 시스템과 추천 시스템 알고리즘 (1) | 2024.05.16 |
| [데브코스][데이터 분석] 데이터 마이닝 실습 (0) | 2024.05.16 |
| [데브코스][데이터 분석] 데이터 마이닝 (0) | 2024.05.16 |
| [데브코스][데이터 분석] 딥러닝 모델을 활용한 문장 분류 실습 (1) | 2024.05.15 |
A/B 테스트 시스템 구성
: A/B 테스트 = 런타임 시스템 + 분석 시스템
런타임 시스템 : 사용자를 A에 둘지, B에 둘지 결정 (버킷 결정, 보통 백엔드 엔지니어+데이터 분석가가 진행)
-> A/B 테스트를 진행할 사용자 버킷 정보를 ETL을 통해 데이터 웨어하우스에 불러옴 (사용자별 행동, 이벤트 로그, 구매정보 등)
-> 분석 시스템 : dbt 등을 통해 분석하기 좋은 테이블로 만들고, 시각화 등 진행
A/B 테스트 구현 방법
- 직접 구현
- SaaS 사용 (Optimizely, VWO 등, 이들은 대부분 front-end 관련 테스트를 하는데 유용함)
-> 보통은 SaaS를 쓰다가 직접 구현하는 식으로 고도화됨
A/B 테스트 전체 과정
- A/B 테스트 제안 (주간미팅)
-> A/B 테스트 실행 & QA
-> Rollout
-> 반복 (주간리뷰, 대시보드 생성, 애자일한 방식 사용(속도 중요)
애자일한 A/B 테스트 시스템 과정
: 알고리즘 생성 -> 배포 -> A/B 테스트 setup -> A/B 테스트 분석 -> 개선
A/B 테스트 트래픽 나누기
: A/B 테스트 런타임 시스템의 기본은 트래픽을 A와 B로 나누는 것이다.
userid VS deviceid
- userid : 로그인한 사용자에게만 하는 테스트일 때 사용, 사용자 등록이 되는 순간 부여되는 유일한 ID
- deviceid : 모든 방문자에게 하는 테스트일 때 사용, 서비스 방문자에게 부여되는 ID로 보통 브라우저 쿠키를 이용해 만들어짐.
=> A/B 테스트의 성격에 따라 userid를 사용할지, deviceid를 사용할지 결정
사용자 미리 나누기 VS 동적으로 나누기
- 미리 모든 사용자를 A/B로 나누기
: 로그인한 사용자를 대상으로 하는 경우
: A/B 테스트 중 신규등록된 사용자에게 적용 불가능
그러나 다수의 A/B 테스트가 동시에 진행될 때, 상호작용을 최소화하는 방향으로 보장할 수 있음 (넷플릭스)
- 사용자를 동적으로 A/B 테스트 진행 중에 나누기
: 일반적으로 사용되는 방법
: 로그인한 사용자이건 아니건 적용, 앞의 방법보다는 bias가 생길 가능성이 있음
트래픽 나누기 로직
1. User ID 혹은 Device ID를 랜덤한 값으로 변경 (보통 MD5 사용)
2. MD5로 바뀐 값(16진수)을 숫자(10진수)로 변경
3. 앞서 나온 값에 Variant의 수(보통 A와 B 2개)로 나머지 연산(modulo) 수행
4. 앞서 나온 결과 값이 0이면 A, 1이면 B
# 파이썬
import hashlib
def split_userid(id):
"""Given an id and the number of variants, returns a bucket number"""
h = hashlib.md5(str(id).encode())
return int(h.hexdigest(), 16) % 2 # num_of_variants
-- SQL
SELECT
user_id,
MOD(STRTOL(LEFT(MD5(user_id),15), 16), 2) variant_id
FROM aa_example
-- LEFT는 오버플로우를 막기 위해 사용
-- STRTOL는 십육진수 문자열을 숫자로 바꾸기 위해 사용
-- MOD는 나머지 계산으로 값을 최종적으로 0과 1로 바꾸기 위해 사용
A/B 테스트 분석
- A/B 테스트의 결과 분석은 가설을 잘 세워야 배우는 것이 있음
=> 경험이 매우 중요함!
- 결과 분석은 객관적이고 공개되어야함
그렇지 않으면 몇 개인에 의해 이상한 결정이 될 수 있음
-> 다양한 사람들이 모인 자리에서 결과를 분석하고 여러 의견을 듣는 것이 좋음
outlier가 A/B 테스트에 미치는 영향
- 어느 서비스나 매출 등에 있어서 매우 큰 소비를 하는 고객이 존재함
-> 이들이 어느 버킷에 들어가느냐가 분석에 큰 영향을 미침 (이런 사람들은 무조건 구매를 하기 때문)
-> 평균 등에서 크게 벗어나는 이상치 값들은 A/B 테스트에서 제거할 필요가 있음
- 봇 유저(scrapping)가 한쪽으로 몰리는 경우
: 서비스의 40~50%의 트래픽은 봇 프래픽일 수 있음.
==> 항상 A/B 테스트 결과는 다양한 관점에서 바라봐야함
잘못된 가설
- survivorship bias
ex. 컴플레인 전화를 하는 사람들의 이탈율을 어떻게 높일까?
-> 그러나, 컴플레인 전화를 하는 사람들은 오히려 이탈율이 높지 않았음 -> 잘못된 가설 설정
시각화
=> AB 테스트 전체 기간에 걸쳐 중요한 지표가 비교 가능해야 한다.
-> 날짜별로 중요 지표가 어떻게 변화하는지 비교해야하며, 이것이 통계적으로 유의미한지 판단해야함.
또한, 사용자 메타 데이터에 따라 필터링이 가능해야함.
<실제 현업에서 A/B 테스트 과정>
1. A/B 테스트 시스템 구축
2. A/A 테스트를 통해 시스템 검증
3. 수십번의 A/B 테스트를 통해 ML 기반 추천 엔진 론칭
'STUDY > DevCourse' 카테고리의 다른 글
| [데브코스][데이터 분석] 애자일 A/B 테스트 (0) | 2024.05.20 |
|---|---|
| [데브코스][데이터 분석] 추천 시스템과 추천 시스템 알고리즘 (1) | 2024.05.16 |
| [데브코스][데이터 분석] 데이터 마이닝 실습 (0) | 2024.05.16 |
| [데브코스][데이터 분석] 데이터 마이닝 (0) | 2024.05.16 |
| [데브코스][데이터 분석] 딥러닝 모델을 활용한 문장 분류 실습 (1) | 2024.05.15 |