
Snowflake를 사용하기 위해 SQL을 통해 기본 테이블을 만들어보자!
SQL Worksheet 생성
본인의 권한을 "ACCOUNTADMIN"으로 설정된 것을 확인하고
위쪽의 Projects -> Worksheets를 눌러 들어간다.
이 후, 오른쪽 상단의 + 버튼을 눌러 "SQL Worksheet"을 선택하여
SQL을 사용할 수 있는 워크시트를 만들어보자.

기본 Worksheets 이름은 시간 정보를 바탕으로 생성된다. 원하는 워크시트 이름으로 적절하게 바꾸자!
(필자는 Setup-Env 로 바꿈)
또한, 위쪽의 ACCOUNTADMIN은 현재 역할(Role)을 의미하며,
COMPUTE_WH는 현재 사용하고 있는 컴퓨팅 리소스를 나타낸다.
이 워크시트를 공유하고 싶다면, Share 버튼을 누르면 된다.

"No Database selected"
-> 내가 실행하는 SQL이 어떤 데이터베이스 밑에 있는 테이블을 대상으로 하는 것인지 나타낸다.
현재는 아무것도 선택되어 있지 않다는 의미이며,
# 데이터베이스 명이 A이고, 테이블명이 B일 때,
# No Database selected 접근하는 방법
A.B
# Database selected 접근하는 방법
B
위와 같이 데이터베이스를 선택했을 때와 선택하지 않았을 때 테이블 접근 방식이 달라진다.
이 부분은 개인의 취향이며, 필자는 데이터베이스를 선택하지 않고 작업을 할 예정이다.
데이터베이스와 스키마 생성
테이블 구조 생성
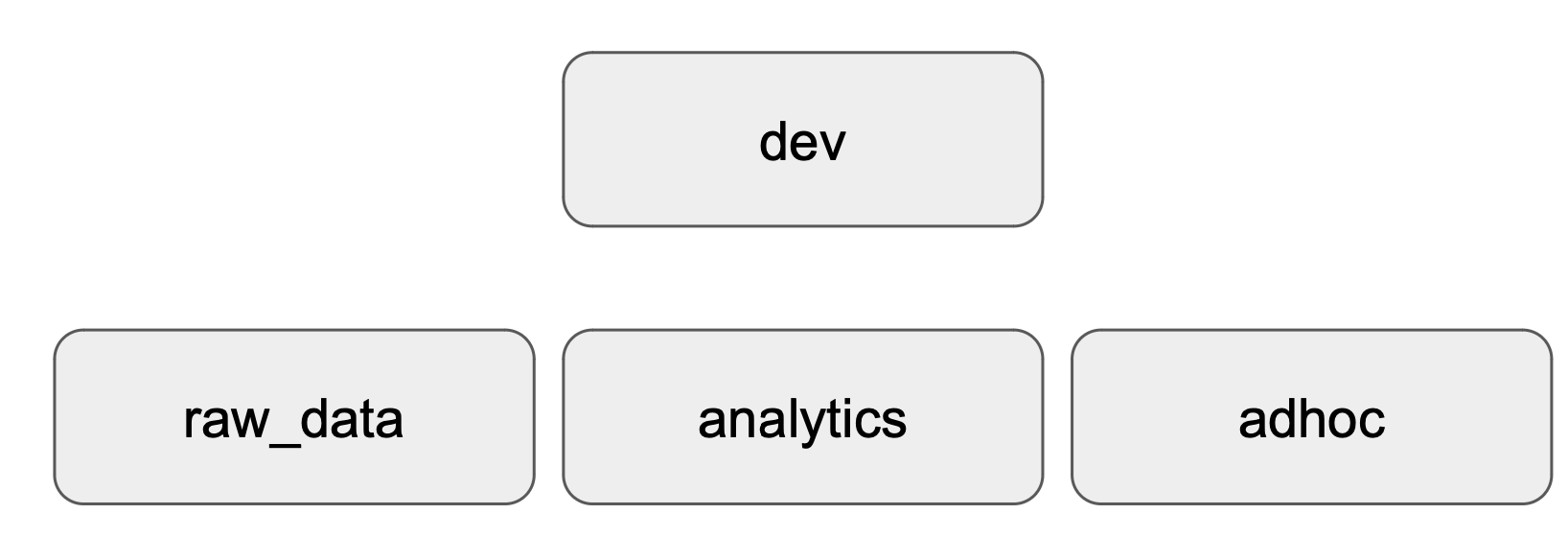
CREATE DATABASE dev;
-- 먼저 3개의 스키마를 생성한다
CREATE SCHEMA dev.raw_data;
CREATE SCHEMA dev.analytics;
CREATE SCHEMA dev.adhoc;
본 실습에서는 위의 구조로 된 데이터베이스와 스키마(테이블)을 생성할 것이다.
- raw_data : ETL로 읽어온 테이블들이 들어가는 스키마.
- analytics : ELT로 만든 새로운 요약 테이블들이 들어가는 스키마 (CTAS를 이용해 만듦)
- adhoc : 개발용/테스트용 스키마
추가적으로, raw_data 스키마 밑에
- user_session_channel
- session_timestamp
- session_transaction
테이블을 만들겠다.
먼저, 비어있는 테이블을 만들자!
CREATE OR REPLACE TABLE dev.raw_data.session_transaction (
sessionid varchar(32) primary key,
refunded boolean,
amount int
);
CREATE TABLE dev.raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);
CREATE TABLE dev.raw_data.session_timestamp (
sessionid varchar(32) primary key,
ts timestamp
);
* 참고) CREATE OR REPLACE TABLE
: 만약 테이블이 존재하면, 지우고 새로 만들어라
-> DROP보다 간편한 명령어! 대신 있는 것을 삭제할 수 있는 가능성이 있음

위의 SQL 명령문을 실행하면 다음과 같이 테이블들이 생성된다.
테이블에 값 넣기
-> 테이블 안의 값은 클라우드 스토리지에 담긴 CSV 파일을 COPY 명령을 통해 복제해오는 방식으로 넣을 것이다!
💡 Snowflake의 COPY 명령
💡 Snowflake의 COPY 명령
: 레코드를 하나씩 적재하지 않고 벌크로 레코드들이 있는 파일을 통째로 적재하는 방식
(Redshift, BigQuery에도 존재하는 명령어)
방식: 레코드들이 있는 파일을 클라우드 스토리지(ex. S3)에 업로드
-> 스토리지에 있는 파일들을 COPY 명령으로 목적 테이블에 벌크로 적재
==> 클라우드 스토리지와 접근 권한 설정이 중요
이 과정에서는 클라우드 스토리지로 S3를 이용할 것임
-> 입력 레코드들이 있는 파일들이 적재될 버킷(S3의 top level 폴더) 생성
-> 그 버킷에 파일 업로드 (CSV 파일)
-> Snowflake에서 테이블별로 어느 CSV파일을 적재할 것(S3에 어디 있는지)인지 지정 필요
-> 이 때, 클라우드 스토리지에 접근할 수 있는 권한 부여 필요
-> IAM을 통해 설정 가능
COPY를 사용해 벌크 업데이트 수행
COPY INTO dev.raw_data.session_timestamp
FROM 's3://xxxxxxx/session_timestamp.csv'
credentials=(AWS_KEY_ID='xxxxxxx' AWS_SECRET_KEY='xxxxxxx')
FILE_FORMAT = (type='CSV' skip_header=1 FIELD_OPTIONALLY_ENCLOSED_BY='"');
* FILE_FORMAT : type -> 파일 타입 / skip_header -> 첫 번째 줄의 헤더 생략 / string 값 적재 시 " 사용하지 않음
* credentials : S3 내의 파일을 접근할 수 있는지 권한 파악 (AWS_KEY_ID, AWS_SECRET_KEY 이용)
-> 이때, AWS의 KEY를 함부로 노출하면 안되기 때문에,
Snowflake의 S3 버킷 엑세스를 위한 전용 사용자를 IAM으로 만듦.
분석에 직접적으로 사용할 새로운 테이블 생성
analytics 스키마 밑에 CTAS를 이용해 새로운 테이블 만들기!
CREATE TABLE dev.analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;
SELECT * FROM dev.analytics.mau_summary LIMIT 10;
'데이터 웨어하우스 > Snowflake' 카테고리의 다른 글
| [Snowflake] Snowflake 무료 체험판 시작하기 (0) | 2024.04.17 |
|---|---|
| [Snowflake] Snowflake 운영과 관리 (0) | 2024.04.17 |