-- 중복이 있는지 확인
SELECT count(1) as cnt, count(distinct restaurant_name) as cnt_distinct
FROM indian_restaurant
이제, 어떤 값에 중복이 있는지 확인해보자.
-- 어떤 값에 중복이 있는지 확인하기
SELECT restaurant_name, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
HAVING cnt > 1
-- 조건에 해당하는 모든 컬럼 출력해보기
SELECT *
FROM indian_restaurant
WHERE restaurant_name in ('7th Heaven', '1441 Pizzeria', '1944 -The HOCCO Kitchen')
ORDER BY restaurant_name, location
-> 같은 이름이지만, 지역이 다른 경우가 있음(중복 발생!)
그럼, 어떤 행으로 유니크하게 모든 행을 구분할 수 있을까?
==> 이 데이터를 행이 하나라도 빠지면 유니크한 행을 찾을 수 없음!
===> 같은 레스토랑 이름이라면 공통적인 속성이 더 크므로, 중복이 발생하겠지만 분석에는 큰 문제가 없다고 생각하겠다.
이제, 본격적인 분석을 해보자.
레스토랑 이름별로 전국에 몇 개나 있는지 세보고, 평균평점과 가격, 배달시간을 체크해보자.
-- 레스토랑 이름별로 전국에 몇 개 있는지, 평균평점, 가격, 배달시간 체크
SELECT restaurant_name,
count(1) as cnt,
avg(rating) as avg_rating,
avg(average_price) as avg_price,
avg(average_delivery_time) as avg_delivery_time
FROM indian_restaurant
GROUP BY 1
ORDER BY 3 DESC
LIMIT 20
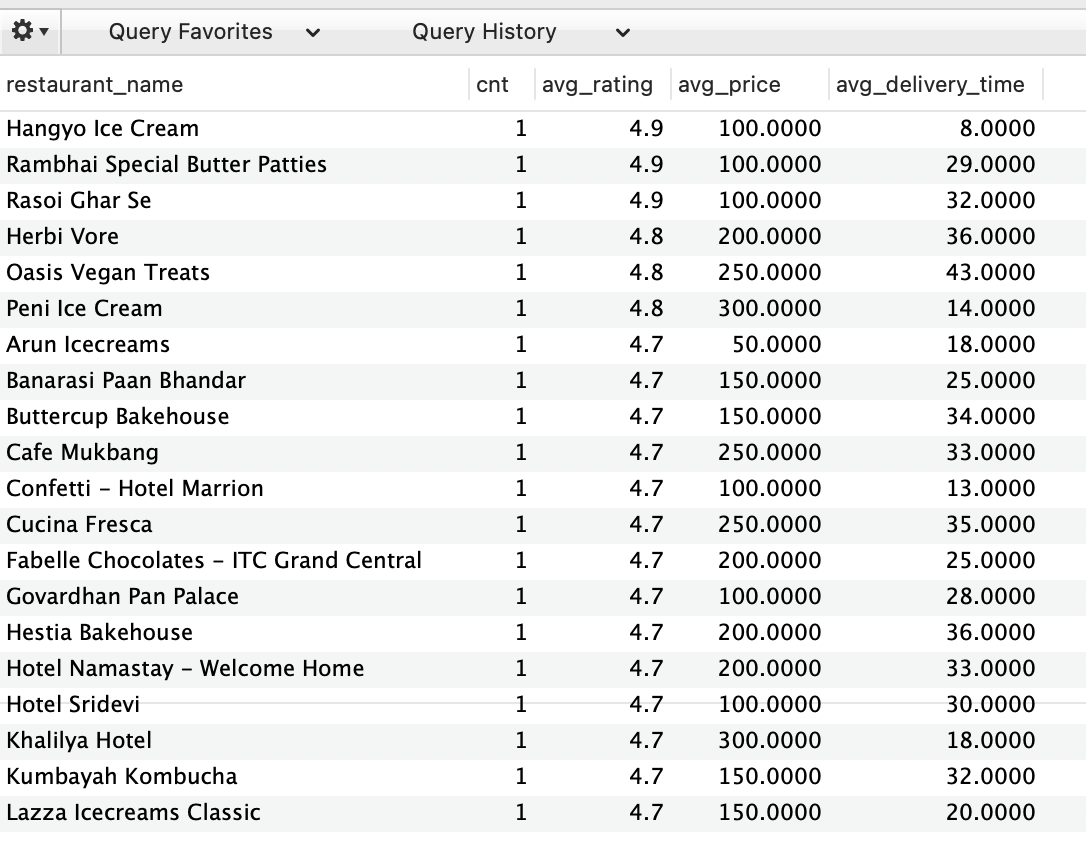
평균 평점이 높은 순으로 상위 20개를 뽑아보았다.
=> 평균평점이 높은 식당 상위 20개는 모두 count가 1임.
==> 즉, 전국에 하나씩만 있는 식당들의 평점이 높음.
그럼, count에 따라 별점 평균의 차이가 있는지 알아보자.
강의에서 제공해준 코드는
WITH counts as (
SELECT restaurant_name, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
)
SELECT CASE cnt
WHEN 1 THEN 'cnt-1'
WHEN 2 THEN 'cnt-2'
ELSE 'cnt-ov3'
END AS cnt_group, avg(rating) as avg_rating
FROM counts INNER JOIN indian_restaurant ON counts.restaurant_name = indian_restaurant.restaurant_name
GROUP BY 1;
이것이다. 그러나 이 코드를 실행하면, 다음과 같은 오류가 발생한다. Table 'DevCourse.indian_restaurant' doesn't exist in engine
with 구문만도 실행해보고, 본 쿼리만도 실행해봤을 때 에러가 발생하지 않는 것을 보니 오타 등의 문제는 아닌듯하며, 같은 파일 내에서 다른 쿼리를 실행했을 때는 정상적으로 동작되는 것을 보니 연결이 제대로 안된 문제도 아닌듯하다.
추측하는 문제는 WITH 구문때문인데,,, 왜 이런 에러가 발생하는지 모르겠다ㅠㅠ 같은 내용의 쿼리를 with구문 없이 작성했을 때는 제대로 된 결과가 나온다.. MariaDB 버전도 다 확인했는데 왜이럴까,, 해결하면 다시 작성해보겠다..
-- count에 따른 별점 평균의 차이
-- count의 종류를 1개, 2개, 3개 이상으로 나눠보자.
SELECT
CASE
WHEN cnt = 1 THEN 'cnt-1'
WHEN cnt = 2 THEN 'cnt-2'
ELSE 'cnt-ov3'
END AS cnt_group,
AVG(rating) AS avg_rating
FROM (
SELECT
restaurant_name,
COUNT(1) AS cnt,
rating
FROM
indian_restaurant
GROUP BY
restaurant_name
) AS counts
GROUP BY
cnt_group;
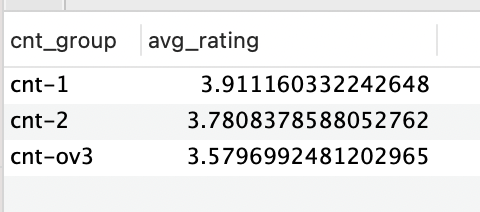
-> 오히려 점포개수가 많아질수록 평균 별점이 높아짐
==> 프랜차이즈는 규격화된 경우가 많기 때문에 따라서 서비스나 맛이 어느정도 보장될 것으로 예상된다.
그러나 단일점포는 서비스, 품질 등의 편차가 크기 때문에 오히려 점포수가 적을수록 평균별점이 낮은 것으로 예상된다.
이를 직접 히스토그램으로 확인해보자.
먼저, 식당이름과 식당이름의 count, 별점이 나오도록 쿼리를 작성하고, 이 결과를 csv로 읽어 히스토그램을 그려보자!
-- 식당이름과 식당이름의 count, 별점 확인
WITH counts as (
SELECT restaurant_name, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
)
SELECT counts.restaurant_name, cnt, rating
FROM counts INNER JOIN indian_restaurant ON counts.restaurant_name = indian_restaurant.restaurant_name
-- 위와 같은 쿼리문(WITH 사용 X)
SELECT counts.restaurant_name, cnt, rating
FROM
(SELECT
restaurant_name,
COUNT(1) AS cnt
FROM
indian_restaurant
GROUP BY
restaurant_name) AS counts
INNER JOIN indian_restaurant ON counts.restaurant_name = indian_restaurant.restaurant_name
이 결과를 바탕으로 파이썬 히스토그램을 그려보면 다음과 같다.
프로그래머스 데브코스 데이터분석 수업자료 중 일부
정리
1. 점포 수가 1개인 식당을 단일 점포, 2개 이상인 식당을 프랜차이즈라고 정의하자.
2. 별점 기준 상위 20개 식당은 모두 단일 점포이다.
3. 평균적으로 프랜차이즈의 평점이 단일 점포보다 높다
4. 단일 점포는 분포가 양끝으로 더 넓게 퍼져 있다. -> 양 극단의 값이 더 많다.
==> 인도의 식당은 프랜차이즈일수록 맛이 보장되어 있고, 단일점포일수록 별점이 낮거나 높은 랜덤한 값을 보인다.
수치형 변수와 별점간의 상관계수 구하기
* Pearson 상관계수 사용
: -1 ~ +1 사이의 값을 보임.
SELECT restaurant_name,
count(1) as cnt,
avg(rating) as avg_rating,
avg(average_price) as avg_price,
avg(average_delivery_time) as avg_delivery_time
FROM indian_restaurant
GROUP BY 1
ORDER BY 3 DESC
위의 쿼리로 나온 결과를 바탕으로 엑셀에서 상관계수를 구해보자!
엑셀의 CORREL 함수를 사용
별점과 점포 개수와의 상관계수 : 0.016
별점과 평균가격과의 상관계수 : -0.007
별점 평균배달시간과의 상관계수 : -0.089
==> 상관계수가 크지는 않지만(뚜렷한 상관계수 X),
음&양의 관계는 맞음. 점포개수가 많을수록 별점이 높다. 배달시간이 길어질수록(높아질수록) 별점이 낮다.
----> 그러나 점포 특정을 파악하여 상관계수를 구해보면 더 좋은 결과가 나올 수 있음
ex. 패스트푸드점의 경우 점포 개수가 많을수록 별점 높을 수 있음
기타 쿼리들
-- 원본 데이터에 점포 개수 추가
WITH counts as (
SELECT restaurant_name, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
)
SELECT indian_restaurant.*, cnt
FROM counts INNER JOIN indian_restaurant ON counts.restaurant_name = indian_restaurant.restaurant_name
-- 지역별 식당 수
SELECT location, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
ORDER BY 2 DESC
LIMIT 20
-- 지역별 식당 수
-- 상위 5% 가게 구하기
WITH cnts as (
SELECT location, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
),
res as (
SELECT location, percent_rank() over (ORDER BY cnt) as cnt_rank
FROM cnts
)
SELECT location
FROM res
WHERE cnt_rant > 0.95
-- 지역별 식당 수
-- 하위 15% 가게 구하기
WITH cnts as (
SELECT location, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
),
res as (
SELECT location, percent_rank() over (ORDER BY cnt) as cnt_rank
FROM cnts
)
SELECT location
FROM res
WHERE cnt_rant < 0.15
-- 그룹 설정 및 각 그룹의 평균 가격 계산
-- 남인도에 위치하는가
SELECT IF(south_indian_or_not = 0, 'south-0', 'south-1') as group_name, AVG(average_price) as avg_price
FROM indian_restaurant
GROUP BY 1
UNION
-- 북인도에 위치하는가
SELECT IF(north_indian_or_not = 0, 'north-0', 'north-1') as group_name, AVG(average_price) as avg_price
FROM indian_restaurant
GROUP BY 1
UNION
-- 패스트푸드점인가
SELECT IF(fast_food_or_not = 0, 'fast-0', 'fast-1') as group_name, AVG(average_price) as avg_price
FROM indian_restaurant
GROUP BY 1
UNION
-- 길거리 음식인가
SELECT IF(street_food = 0, 'street-0', 'street-1') as group_name, AVG(average_price) as avg_price
FROM indian_restaurant
GROUP BY 1
--> 그룹에 따른 가격 차이 발생
-- 각 지역별 전체 식당 수와 속성별 식당 수
WITH base as (
SELECT location, south_indian_or_not, north_indian_or_not, fast_food_or_not, street_food)
FROM indian_restaurant
WHERE location IN ('Rishikesh', 'Shimla')
)
SELECT location,
count(1) as tot_cnt,
SUM(south_indian_or_not) as south_cnt,
SUM(north_indian_or_not) as north_cnt,
SUM(fast_food_or_not) as fast_cnt,
SUM(street_food) as street_cnt
FROM base
GROUP BY 1
--> 어떠한 위치에 있는 식당들이 왜 더 저렴한지 확인할 수 있음
(어떠한 위치에 있는지, 길거리음식을 파는지, 패스트푸드점이 많은지 등을 파악할 수 있음)
-- 지역에 따른 평균 별점, 지역에 있는 식당이 몇 개인지
SELECT location, avg(rating) as avg_rating, count(1) as cnt
FROM indian_restaurant
GROUP BY 1
ORDER BY 2
LIMIT 10
7-2. 실전 데이터 분석 사례 2 : Global AI, ML, Data Science Salary
-- 연도에 따른 데이터 개수 세기
SELECT work_year, count(1)
FROM salary
GROUP BY 1
ORDER BY 1
--> 2020, 2021년의 데이터 양은 상대적으로 적으므로, 2022년과 2023년의 데이터만 분석해보도록 하자.
-- 연도에 따른 평균 연봉
SELECT work_year, AVG(salary_in_usd) as usd_salary
FROM salary
WHERE work_year in (2022, 2023)
GROUP BY 1
ORDER BY 1
--> 2022년에 비해 2023년의 연봉이 오름
==> 왜 연봉이 올랐는지 확인해보자.
-- 어떤 컬럼이 연봉에 영향을 미쳤는가
-- 숙련도, 직무, 거주국가, 회사위치, 회사사이즈
SELECT experience_level, AVG(salary_in_usd) as usd_salary
FROM salary
WHERE work_year in (2022, 2023)
GROUP BY 1
ORDER BY 2
--> 숙련도가 높을수록 높은 연봉을 받음
- 직무에 따른 연봉 차이 => 매우 큼
- 거주 국가에 따른 연봉 차이 => 매우 큼
- 재택 근무에 따른 연봉 차이 => 매우 큼
- 회사 사이즈에 따른 연봉 차이 => 고용인원이 50명 미만일 때 가장 낮고, 나머지는 큰 차이 없음
-- 2022년에서 2023년으로 넘어갈 때 값의 변화
WITH bef as (
SELECT work_year, experience_level, count(1) as cnt_2022
FROM salary
WHERE work_year = 2022
GROUP BY 1, 2
),
aft as (
SELECT work_year, experience_level, count(1) as cnt_2023
FROM salary
WHERE work_year = 2023
GROUP BY 1, 2
)
SELECT bef.*, aft_cnt_2023
FROM bef INNER JOIN aft ON bef.experience_level = aft.experience_level
-> 숙련도별로 구분한 직원 수임
=> 이를 바탕으로 엑셀에서 분석을 해보면..
22년에 비해 23년에 고연봉자들을 증가하였고, 저연봉자들이 감소함
==> 이 때문에 평균적으로 2022년에 비해 2023년의 평균 연봉이 증가한 결과를 보였음
+ 이와 유사하게 회사 크기별 2022년과 2023년을 비교해봄.
=> 저연봉 회사가 줄어들었고, 고연봉 회사가 늘어났음
==> 이 때문에 23년에 평균 연봉이 높아짐!
* 2022년에 비해 2023년에 평균 연봉이 증가한 이유는 시니어 비중이 높아지고 고연봉 회사가 많아졌기 때문이다.
(변수간 상관관계는 파악 불가)
다음으로, 연도별 원격 근무 비중을 확인해보자.
-- 연도별 원격 근무 비중
SELECT work_year, AVG(remote_ratio) as avg_remote_ratio
FROM salary
WHERE work_year in (2022, 2023)
GROUP BY 1
ORDER BY 1
-> 2022년에 비해 2023년의 원격 근무 비중이 줄어들었음
숙련도별 평균 원격 근무 비중, 회사 사이즈별 원격 근무 비중, 해외 근무자 비중을 분석해본 결과
2022년에 비해 2023년의 원격 근무 비중이 줄어든 이유는
시니어 직원 비중이 높아지고, 해외 근무자 비중이 줄어들었기 때문이다.
(변수간 상관관계 파악은 불가)
다음으로, 비슷한 직무명이 많으므로, 대표 키워드를 가지고 그룹화한 후 평균 연봉을 비교해보자.
-- 직무별 평균 연봉 비교
SELECT CASE
WHEN job_title LIKE '%Scientist%' THEN 'S'
WHEN job_title LIKE '%Director%' THEN 'D'
WHEN job_title LIKE '%Engineer%' THEN 'E'
WHEN job_title LIKE '%Anaylst%' THEN 'A'
WHEN job_title LIKE '%Architect%' THEN 'AC'
WHEN job_title LIKE '%Consultant%' THEN 'C'
WHEN job_title LIKE '%Manager%' THEN 'M'
WHEN job_title LIKE '%Specialist%' THEN 'SP'
WHEN job_title LIKE '%Practitioner%' THEN 'P'
ELSE 'OTHER'
END AS job_group, AVG(salary_in_usd) as avg_salary, AVG(remote_ratio) as avg_remote, count(1) as cnt
FROM salary
GROUP BY 1
ORDER BY 2
--> 연봉이 가장 많고, 재택비중이 많은 직무는 director임
-- 직무별 해외 근로자 비율
WITH base as (
SELECT CASE
WHEN job_title LIKE '%Scientist%' THEN 'S'
WHEN job_title LIKE '%Director%' THEN 'D'
WHEN job_title LIKE '%Engineer%' THEN 'E'
WHEN job_title LIKE '%Anaylst%' THEN 'A'
WHEN job_title LIKE '%Architect%' THEN 'AC'
WHEN job_title LIKE '%Consultant%' THEN 'C'
WHEN job_title LIKE '%Manager%' THEN 'M'
WHEN job_title LIKE '%Specialist%' THEN 'SP'
WHEN job_title LIKE '%Practitioner%' THEN 'P'
ELSE 'OTHER'
END AS job_group, IF(employee_residence = 'US', 'In-US', 'Out-US') as residence_group
FROM salary
),
g_1 as (
SELECT job_group, residence_group, count(1) as group_cnt
FROM base
GROUP BY 1, 2
),
g_2 as (
SELECT job_group, count(1) as group_cnt
FROM base
GROUP BY 1
)
SELECT g_1.gob_group, residence
FROM g_1 INNER JOIN g_2 ON g_1.job_group = g_2.job_group
-- 시즌별 데이터 비중
SELECT season, count(1) as cnt
FROM nba
GROUP BY 1
ORDER BY 1
-> 시즌별 데이터 개수의 편차가 크지 않고 고름.
-- 데이터의 중복 파악
SELECT count(1) as cnt, count(distinct season, player_name) as d_cnt
FROM nba
-> 4개의 중복 발생
-- 어디에서 중복이 일어났는지 파악
WITH dups as (
SELECT player_name, season, count(1) as cnt
FROM nba
GROUP BY 1, 2
HAVING cnt > 1
),
tot as (
SELECT *
FROM nba
)
SELECT tot.*
FROM tot INNER JOIN dups ON tot.player_name = dups.player_name and tot.season = dups.season
-> 이름은 같지만 다른 정보를 가진 선수 찾음 -> 동명이인인 선수들임
선수들의 키, 몸무게, 나이가 시즌별로 어떻게 바뀌었는지 찾아보자!
-- 시즌별 선수들의 평균 정보
SELECT season,
AVG(player_height) as height,
AVG(player_weight) as weight,
AVG(gp) as gp,
AVG(pts) as pts,
AVG(reb) as reb,
AVG(ast) as ast
FROM nba
GROUP BY 1
ORDER BY 1