[데브코스][데이터 분석] 데이터 시각화
< 7주차 Python 데이터 분석과 통계화 시각화 (3) >
시각화(Visualization)
: 시각화는 데이터 분석 결과를 plot 이나 graph를 통해 시각적으로 전달할 수 있는 방법
-> 분석 내용 한 눈에 확인 가능, 통계 수치상으로 파악하기 쉽지 않은 내용 파악 가능(ex. 데이터 분포)
matplotlib
- 파이썬의 라이브러리. numpy나 pandas의 자료구조 시각화 가능
import matplotlib.pyplot as plt
plt.plot()
# 플롯 확인 가능
plt.show()
# 파일 저장
# dpi=500 : 해상도
plt.savefig('filename', dpi=500)
# 타이틀 지정
plt.title("xxx")
# 축 label
plt.xlabel("00", fontsize=10)
# 축 눈금
plt.xticks(rotation=90)
# 범례 설정
plt.legend(['ddd', 'fff', 'ggg'], fontsize=15)
# 축 끝값
plt.xlim(0, 5)
plt.ylim(0, 5)
+ marker, markersize, linestyle, color, alpha 등을 설정해 점모양, 점크기, 선모양, 색깔, 투명도 들 조절 가능
산점도(scatter plot)
: x, y 좌표로 이루어진 데이터들을 점으로 표현하는 플롯
colors = [0]*25 + [1]*25
area = x * y * 250
plt.scatter(x, y, s=area, c=colors)
# s는 점 크기, c는 점 색깔
s는 점 크기, c는 점 색깔
barplot
: 수직 막대 그래프
plt.bar(x, y, align='center', alpha=0.7, color='red')
# align: 설명이 막대의 어디에 위치하는가
# alpha: 투명도
barhplot
: 수평 막대 그래프
plt.barh(x, y, align='center', alpha=0.7, color='green')
=> width, align 등의 옵션으로 막대의 위치 조정 가능
=> color, alpha 옵션으로 막대의 색깔 조정 가능
subplot
: subplot과 bar, barh를 함께 사용하면 비교 그래프 그리기 가능
# subplots 생성
fig, axes = plt.subplots()
axes.bar(x - width/2, y_1, width, align='center', alpha=0.5)
axes.bar(x + width/2, y_2, width, align='center', alpha=0.8)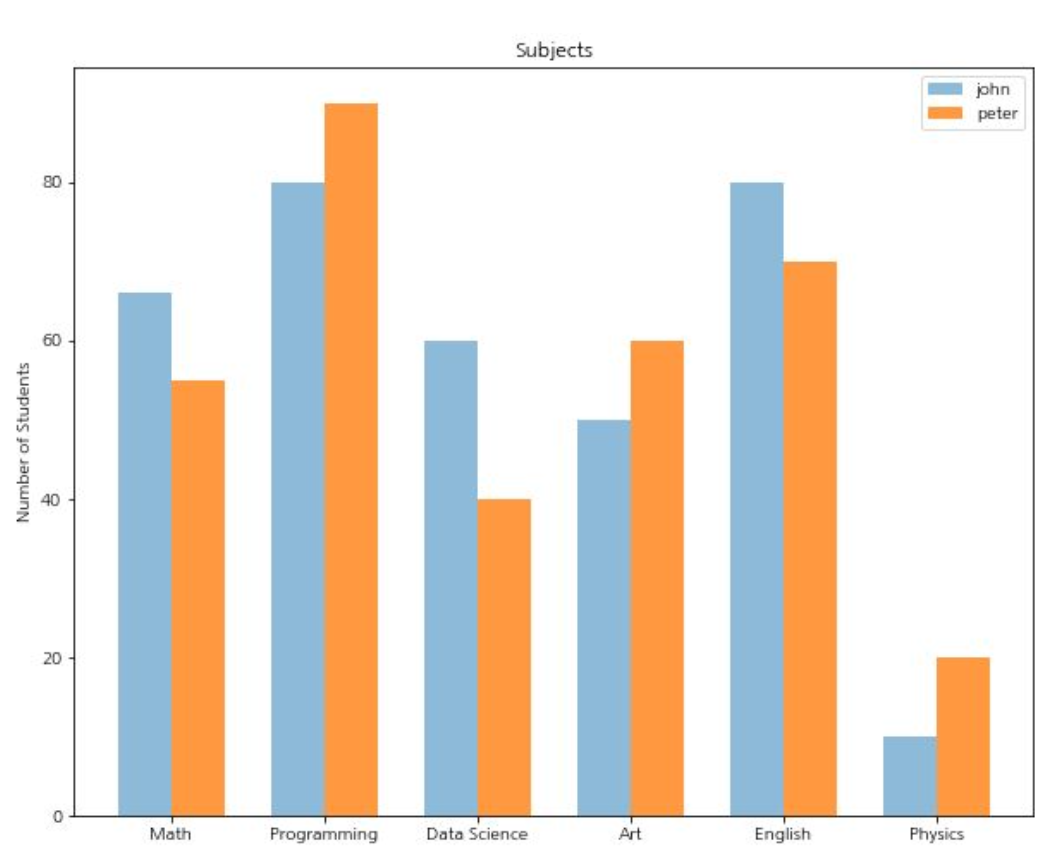
histogram
: 히스토그램은 도수분포표를 그래프로 나타낸 것.
가로축은 변수값, 세로축은 빈도나 비율
: bins 옵션으로 막대 개수 조절 가능
: density=True인 경우 frequency 대신 density를 y축에 나타냄
plt.hist(x, bins=30)
# density=True 값을 통하여 Y축에 frequency 대신 density
plt.hist(x, bins=30, density=True)
piechart
: 클래스간의 비율을 효과적으로 보여줌

- explode: 파이에서 툭 튀어져 나온 비율
- autopct: 퍼센트 자동으로 표기
- '%.1f%%': 소수점 1자리까지 표기
- shadow: 그림자 표시
- startangle: 파이를 그리기 시작할 각도
- texts, autotexts 인자를 리턴 받습니다
다룰 때 활용합니다
- → texts는 label에 대한 텍스트 효과를, autotexts는 파이 위에 그려지는 텍스트 효과
# texts, autotexts 인자를 활용하여 텍스트 스타일링을 적용합니다
patches, texts, autotexts = plt.pie(sizes, # 각 클래스의 비율
explode=explode, # 몇 번째 클래스가 얼마큼 튀어나오게
labels=labels, # 이름
# autopct='%.2f%%', # 소수점 둘째자리까지 표시
autopct='%.1f%%',
shadow=True, # 그림자 표시
startangle=90) # 파이를 그리기 시작할 각도(90도)
heatmap
- plt.matshow()
: 다양한 값을 갖는 숫자 데이터를 열분포 형태처럼 시각화
ex. 지도이미지 위에 인구 빈도 분포 표현
# 컬러맵 종류 지정 -> 가시성이 달라짐
cmap = plt.get_cmap('PiYG')
# cmap = plt.get_cmap('BuGn')
# cmap = plt.get_cmap('Greys')
# cmap = plt.get_cmap('bwr')
plt.matshow(arr, cmap=cmap)
# 어떤 색이 어떤 값을 나타내는지 추가적으로 제공해줌
# aspect: 가로세로 비율, shrink: 전체적인 크기 조정
plt.colorbar(shrink=0.8, aspect=10)
colormaps
: plt.plasma(), plt.jet(), nipy_spectral() 등과 같은 함수 이용
-> 변수의 복잡한 관계를 보일 때 효과적
plt.subplot(2, 2, 1) plt.scatter(arr[0], arr[1], c=arr[1])
plt.viridis()
plt.title('viridis')
plt.colorbar()
plt.subplot(2, 2, 2) plt.scatter(arr[2], arr[3], c=arr[3])
plt.plasma()
plt.title('plasma')
plt.colorbar()
# 등..
텍스트 삽입
plt.text(x위치, y위치, 텍스트, font)
font1 = {'color': 'darkred',
'weight': 'normal',
'size': 16}
plt.hist(a, bins=100, density=True, alpha=0.7, histtype='step')
plt.text(1.0, 0.35, 'np.random.randn()', fontdict=font1)
그래프 스타일 설정
plt.style.use()
# 기본 스타일
plt.style.use('default')
# 사용가능한 스타일 조회
plt.style.available
# 다양한 스타일
plt.style.use('ggplot')
plt.style.use('Solarize_Light2')
: 미리 만들어둔 그래프 스타일 사용 가능
* 각각의 스타일 관련 파라미터(rcParams)를 통해 커스텀 가능
plt.style.use('default')
plt.rcParams['figure.figsize'] = (6, 3)
plt.rcParams['font.size'] = 12
plt.rcParams['lines.linewidth'] = 3
plt.rcParams['lines.linestyle'] = '-'
subplots
plt.subplots(행 개수, 열 개수)
: 하나의 화면 안에 여러 플롯 가능
* 원하는 위치(axes[행, 열]) 에 원하는 플롯 삽입 가능
* 원하는 스타일 조정 가능
# sharex=True, sharey=True로 중복된 축 한 번만 표시 가능
fig, axes = plt.subplots(2, 2, sharex=True, sharey=True, squeeze=True)
axes[0][0].plot(x, np.sqrt(x), 'gray', linewidth=3, label='y=np.sqrt(x)')
axes[0][0].set_title('Graph 1')
axes[0][0].legend()
이중 y축 표시
: 두 종류의 데이터를 동시에 하나의 그래프에 표시
: ax1.twinx()로 ax1과 x축을 공유하는 새로운 ax2 생성
fig, ax1 = plt.subplots()
ax1.set_xlabel('X-Axis')
ax1.set_ylabel('1st Y-Axis')
line1 = ax1.plot(x, y1, color='green', label='1st Data')
ax2 = ax1.twinx()
ax2.set_ylabel('2nd Y-Axis')
line2 = ax2.plot(x, y2, color='deeppink', label='2nd Data')
lines = line1 + line2
labels = [l.get_label() for l in lines]
ax1.legend(lines, labels, loc='upper right')
plt.show()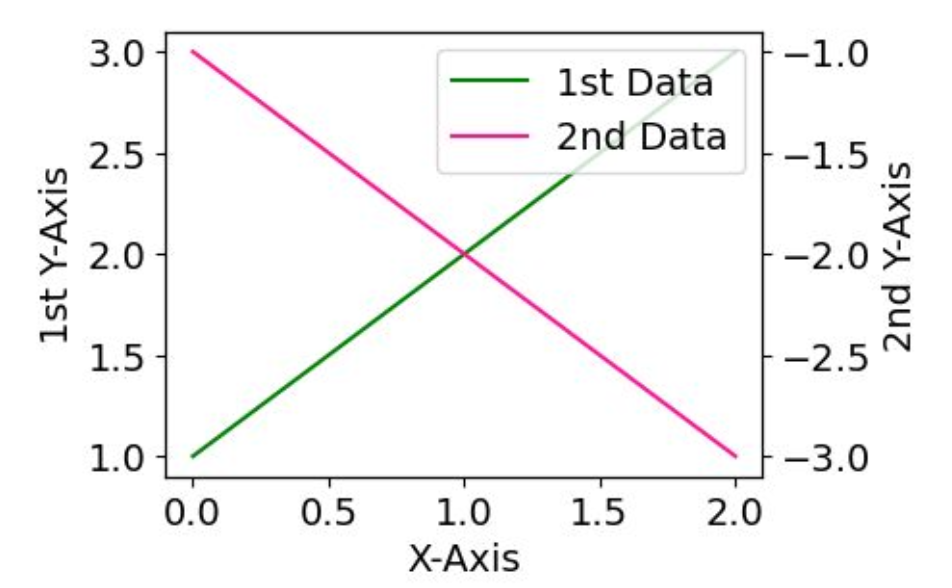
boxplot
: 수치 데이터의 분포 표현
- notch=True : 중앙값의 95% 신뢰구간을 노치 형태로 표시
- subplot()과 boxplot()을 함꼐 사용하면 한 그림 안에 여러 botplot 그리기 가능
- box['whiskers'], box['median'] 등의 key 호출 후 item.get_ydata()로
각 box의 whisker, median, outlier 조회 가능
violinplot
: boxplot과 유사
: boxplot에 kd 곡선을 같이 그린 형태 -> 세밀한 분포 확인 가능
* quantiles 옵션을 이용해 표시할 분위수 조정 가능

violin = ax.violinplot([data_a, data_b, data_c],
showmeans=True,
showextrema=True,
# showmedians=True,
quantiles=[[0.25, 0.75], [0.1, 0.9],[0.3, 0.7]])
seaborn
: matplotlib을 기반으로 하며, matplotlib보다 pandas에 조금 더 친화적임
: seaborn은 python에서 통계 그래픽을 만들기 위한 라이브러리
: pandas df와 직곽적으로 연계되기에 쉽고 빠르게 시각화 가능
1) Relplot: 2개 이상의 변수간의 관계를 나타내는 플롯 -> scatterplot, lineplot
2) Displot: 1개 이상의 변수 값의 분포를 나타내는 플롯 -> histplot, kdeplot, ecdfplot, rugplot
3) Catplot: 범주형 데이터의 분포를 효과적으로 나타내는 플롯 -> stripplot, boxplot 등
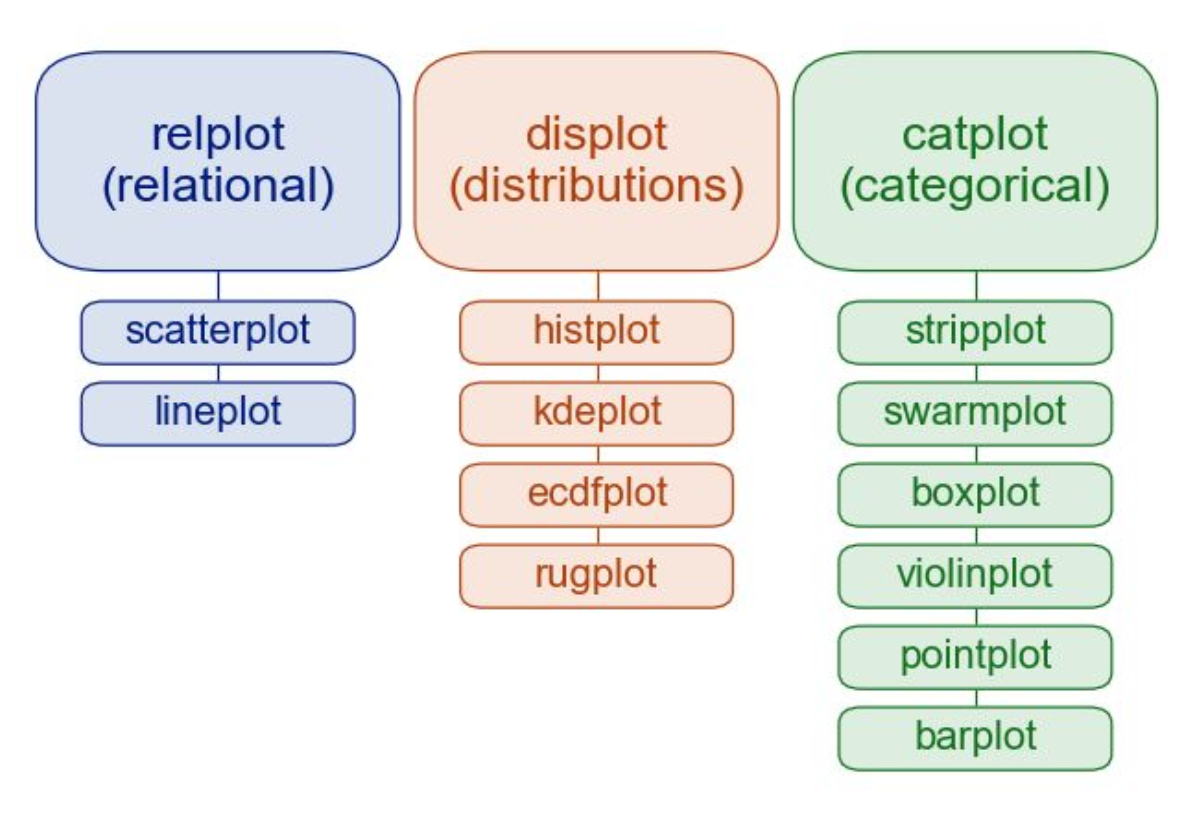
Relplot
: 데이터셋의 변수가 어떻게 서로 연관되어 있는지,
이 관계가 다른 변수에 어떻게 의존하는지 도움주는 시각화
-> scatter plot, line plot 가능
-> 색상, 크기 및 스타일을 사용해 최대 3개의 추가 변수 매핑 가능
# scatter plot
sns.relplot(data=tips, x="total_bill", y="tip")
sns.scatterplot(data=tips, x="total_bill", y="tip")
# line plot
sns.relplot(data=dowjones, x="Date", y="Price", kind="line")
sns.lineplot(data=dowjones, x="Date", y="Price")
scatter plot
: relplot은 기본적으로 scatter plot 이용함
tips = sns.load_dataset("tips")
sns.relplot(data=tips, x="total_bill", y="tip")
sns.scatterplot(data=tips, x="total_bill", y="tip")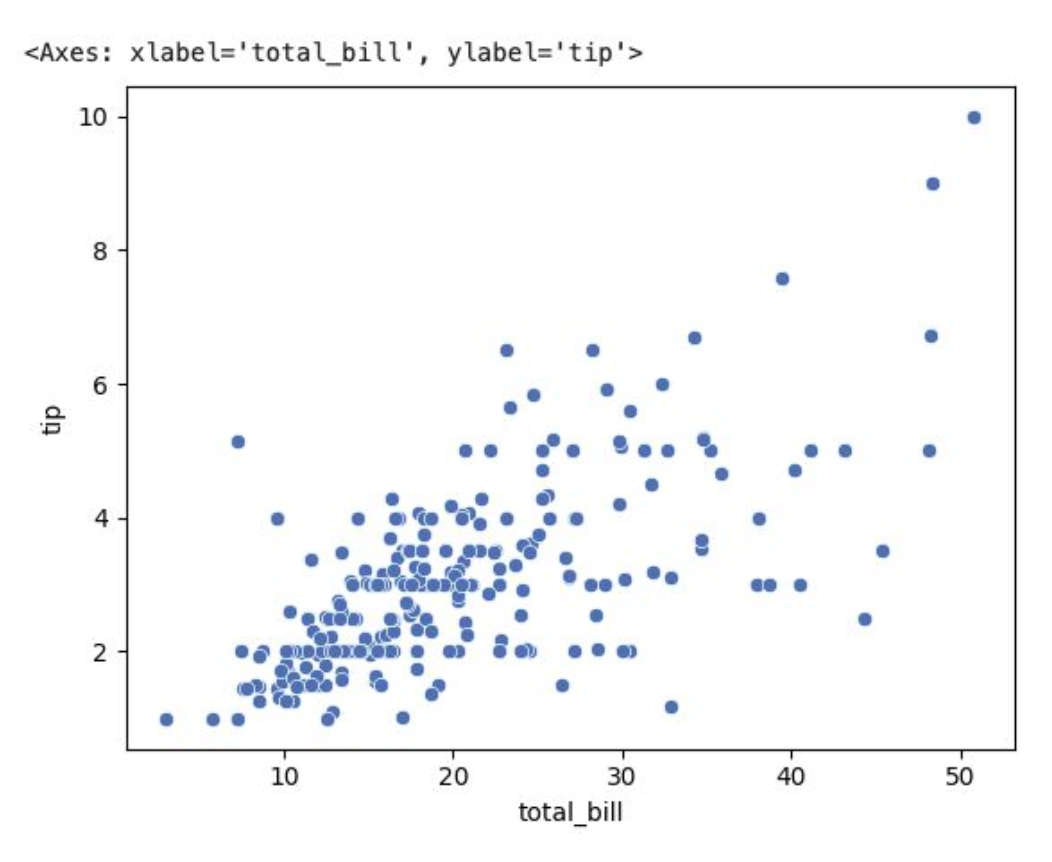
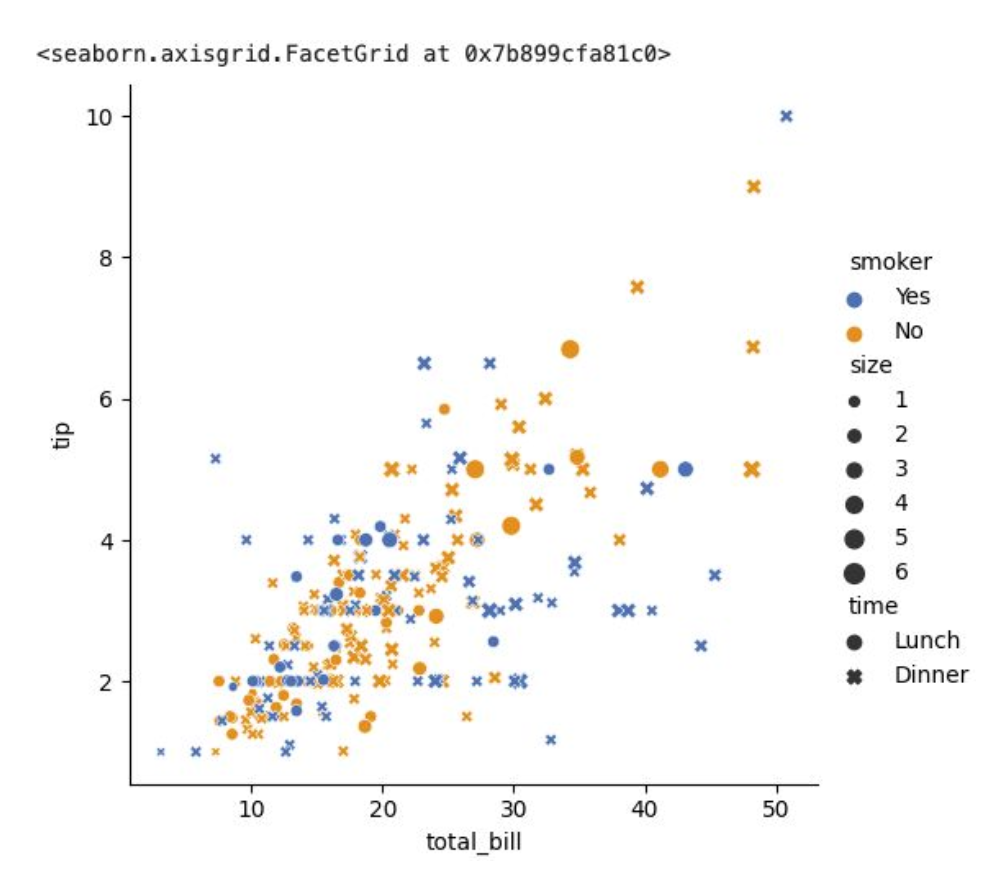
+ hue, size, style을 통해 데이터포인트가 갖는 categorical 변수값 표현 가능 (시각화의 핵심!)
hue: 점의 색깔 조정을 통해 다르게 표시
-> hue가 갖는 값이 연속형 변수면 색이 paletter 형태로 표현됨
size: 점의 사이즈 조정을 통해 다르게 표시
-> sizes=(a, b) 옵션을 통해 점들의 크기 조정 가능
style: 점의 스타일 조정을 통해 다르게 표시
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker",
style="time",size="size"
)
line plot
: 시간과 같이 지속성을 가진 변수와 다른 변수의 관게를 나타낼 때 효과적
dowjones = sns.load_dataset("dowjones")
sns.relplot(data=dowjones, x="Date", y="Price", kind="line")
sns.lineplot(data=dowjones, x="Date", y="Price")

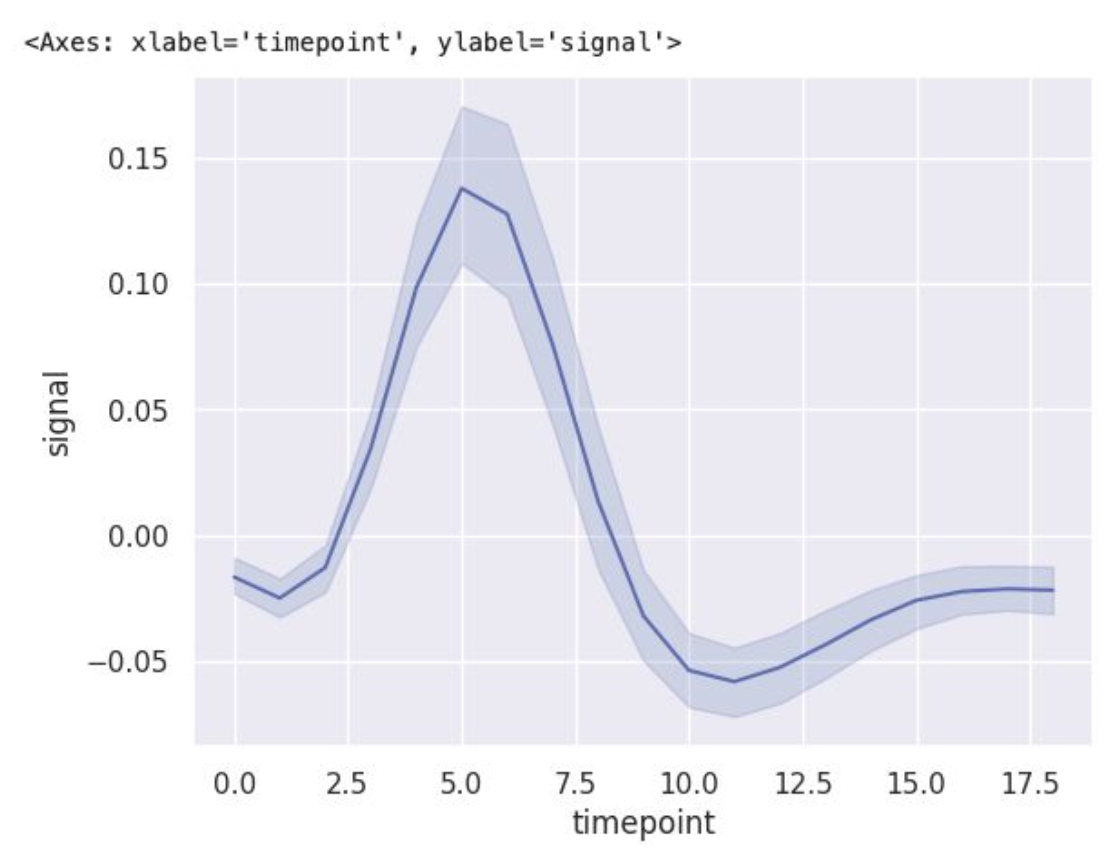
* x축 값 하나에 따른 y값이 하나가 아닌 다양한 값을 가질 수 있음.
이 때, 기본적으로 iineplot은 여러 값들을 모아서 평균을 선으로, 95% 신뢰구간을 색으로 표현
(신뢰구간을 표시하지 않으려면 errorbar=None)
(표준편차 범위로 표시하고 싶으면 errorbar='sd')
* hue를 통해 연속형 변수를 구분하여 lineplot 가능
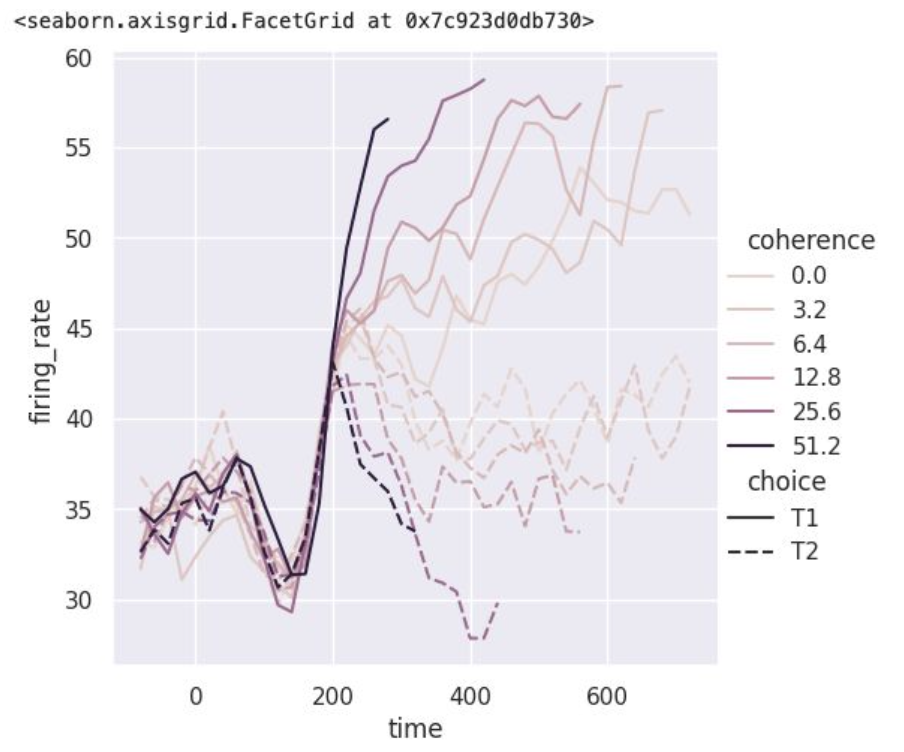
* palette로 선의 색 차이 조정 가능
palette = sns.cubehelix_palette(light=.9, n_colors=6)
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
palette=palette,
kind="line", data=dots)
# light: 값이 커질수록 가장 밝은 색의 명도가 높아짐
# n_colors: 가질 수 있는 카테고리 개수
# size: 굵기 조정
* 추가: facet
: 변수가 많아질수록 한 플롯 안에서 표현하면 가시성이 떨어짐
-> 여러 플롯으로 나눠 분석하는 것(facet)
-> col, row를 이용해 플롯을 나누고 height로 플롯의 크기 조정
sns.relplot(x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3.5,
kind="line", estimator=None, data=fmri)
displot
: 변수 하나 혹은 두 개의 분포를 나타낼 때, 해당 변수 값이 가지는 분포 및 범위를 파악 가능
: 기본적으로 히스토그램을 그려줌
sns.histplot(penguins, x="flipper_length_mm")
sns.displot(penguins, x="flipper_length_mm")
histoplot
: binwidth 혹은 bins를 사용해 막대 너비 조절 가능
: 변수가 이산형이면, discrete=True로 x축 값 중앙에 막대가 위치하게 할 수 있음
: shrink 옵션으로 막대 간 공간 조절 가능
sns.displot(tips, x="size", discrete=True, shrink=.7)
: hue옵션으로 추가 변수를 조건으로 한 분포를 시각화 가능
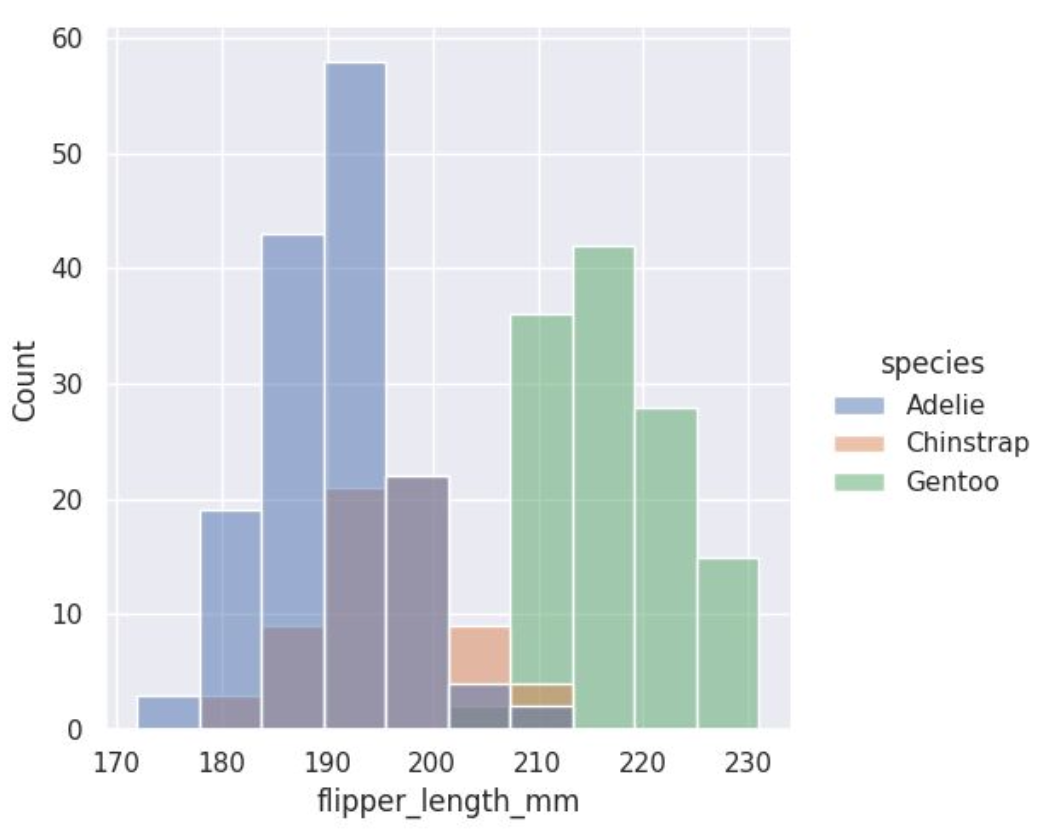
: 막대간 겹쳐지는 부분의 경우 element=step 옵션 or multiple=stack 옵션 사용 가능
(카테고리 변수일 경우 multiple=dodge 사용 가능)
sns.displot(penguins, x="flipper_length_mm", hue="species", element="step")
sns.displot(penguins, x="flipper_length_mm", hue="species", multiple="stack")
: col이나 row를 통해 변수에 따른 여러 플롯 그릴 수 있음
: stat='probablity' 옵션으로 모든 막대의 높이의 합이 1이 되게 만들 수 있음(빈도의 비율값)
kdeplot
: 히스토그램과 다른 부드러운 곡선으로 이어진 분포 시각화 가능
: bw_adjust를 이용해 곡선을 세밀하게 혹은 더 부드럽게 표현 가능
sns.displot(penguins, x="flipper_length_mm", kind="kde", bw_adjust=.25)
: hue를 이용해 변수간 분포 시각화 가능
: fill=True 옵션으로 곡선 아래 색칠된 형태로 표현 가능
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="kde", fill=True)
heatmap/contour
변수가 2개 들어간 경우, heatmap은 histogram과 유사
* 기본적으로 displot은 히트맵을 그림
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm")
: cbar=True로 색깔에 따른 빈도값 표현 가능
contour은 kdeplot과 유사
* kind를 지정해주면 contour 그려줌
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", kind="kde")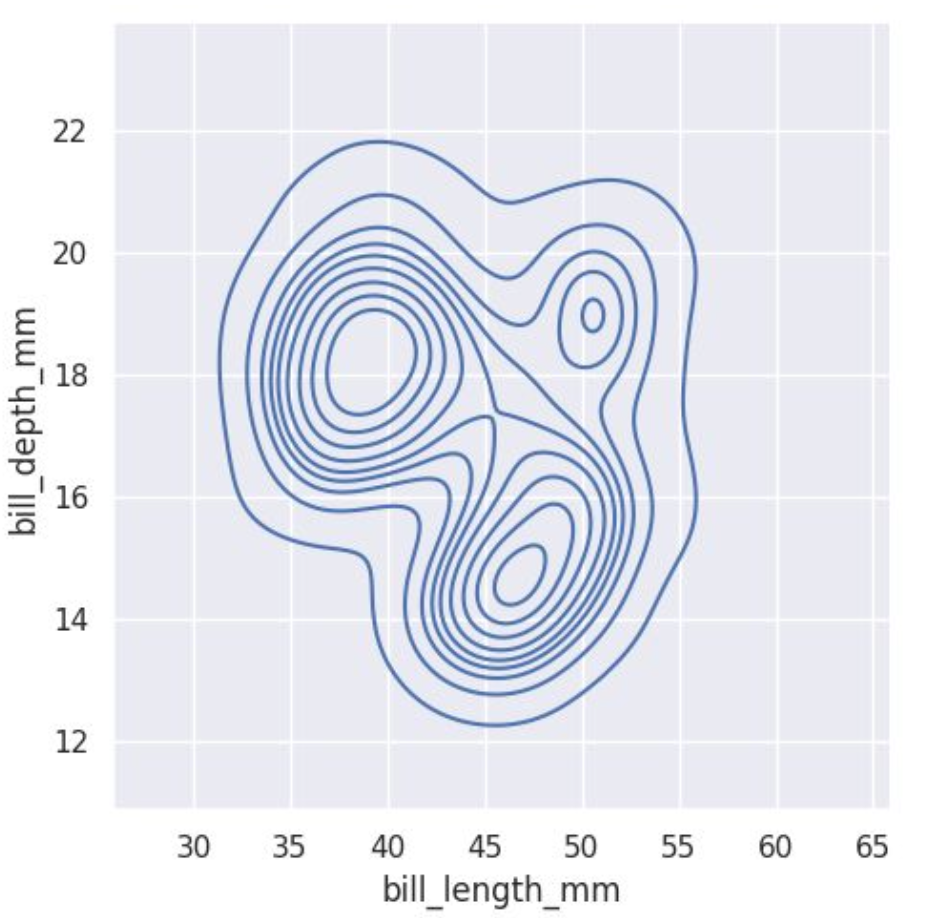
: thresh, levels로 선의 간격 조정 가능
joint plot
: 2개 변수 간 분포와 각 변수의 분포를 동시에 보여줌
: 기본적으로 scatter plot과 histogram을 그리며,
kind='kde' 설정 시 contour plot과 kde plot을 그려줌
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
pair plot
: 각 변수들간의 pairwise 관계 시각화 가능
-> 고려할 변수가 많을 때, 상관관계 파악 시 사용
sns.pairplot()
catplot
replot에서 다루고자 하는 변수가 범수형 or 이산형 데이터인 경우 scatter plot이나 line plot 대신 catplot을 사용하여 효과적인 시각화 가능
- 범주형 산점도: strip plot, swarm plot
- 범주형 분포도: box plot, violin plot
- 범주형 추정도표: bar plot, point plot
-> cat plot의 기본 플롯은 strip plot.
범주형 산점도 - strip plot
: 한쪽 변수가 범주형 데이터만 산점도라고 생각하면 됨
: 한 범주에 속하는 모든 점이 범주형 변수에 해당하는 축을 따라 동일한 위치에 존재함
: jitter 옵션으로 좌우 퍼진 정도 조절 가능
sns.catplot(data=tips, x="day", y="total_bill")
sns.catplot(data=tips, x="day", y="total_bill", jitter=.3)
sns.catplot(data=tips, x="day", y="total_bill", jitter=False)
* 범주형 데이터가 아닌 경우에도 자동으로 범주형 데이터로 취급함
이 때, native_scale 옵션을 사용하면 x축 데이터의 분포 보존 가능
# 왼쪽 그래프
sns.catplot(data=tips.loc[tips['size']!=3], x="size", y="total_bill")
# 오른쪽 그래프
sns.catplot(data=tips.loc[tips['size']!=3], x="size", y="total_bill", native_scale=True)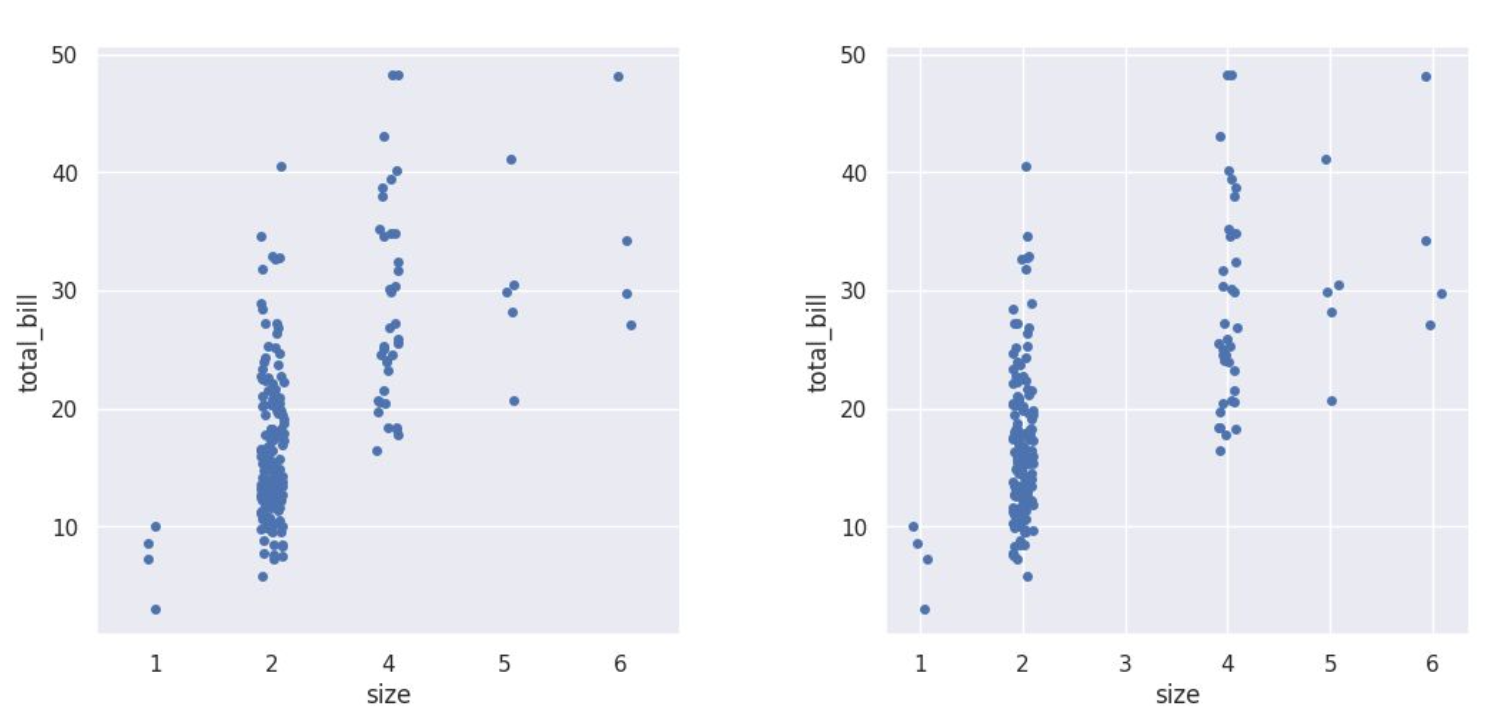
* order 옵션을 사용해 범주형 변수의 순서 바꾸기 가능
sns.catplot(data=tips, x="smoker", y="tip", order=["No", "Yes"])
범주형 산점도 - swarm plot
: 점들의 중첩을 방지하는 알고리즘을 사용하여 시각화
: 상대적으로 데이터 수가 적은 경우에만 잘 작동. but, 관측치 분포를 더 잘 표현할 수 있음
: hue를 사용하여 필터 추가 가능(size나 style 지원 X)
sns.swarmplot(data=tips, x="day", y="total_bill")
sns.catplot(data=tips, x="day", y="total_bill", kind="swarm")
sns.catplot(data=tips, x="day", y="total_bill", hue="sex", kind="swarm")
범주형 분포도 - box plot
: 데이터셋의 크기가 커짐에 따라 각 범주내의 값 분포에 대해 제공할 수 있는 정보가 제한됨
이 때, box plot 사용 가능
# hue 옵션 추가 가능
sns.catplot(data=tips, x="day", y="total_bill", hue="smoker", kind="box")
* boxen plot : 분위수를 자세히 표시 가능
sns.boxenplot(data=diamonds.sort_values("color"), x="color", y="price")
sns.catplot(
data=diamonds.sort_values("color"),
x="color", y="price", kind="boxen",
)
범주형 분포도 - violin plot
: box plot과 kde 곡선을 결합한 형태
# 1
sns.violinplot(data=tips, x="total_bill", y="day", hue="sex")
# 2
# bw_0.5 : 끝까지 그려지는 것이 아닌 조금 잘려서 그려짐
# cut: 0을 기준으로 값이 잘림
sns.catplot(
data=tips, x="total_bill", y="day", hue="sex",
kind="violin", bw_adjust=.5, cut=0)
** box plot이나 violin plot을 swarm plot과 결합 가능
# violin plot과 swarm plot 결합
# inner=None 을 통해 내부의 box plot 제거
g = sns.catplot(data=tips, x="day", y="total_bill", kind="violin", inner=None)
sns.swarmplot(data=tips, x="day", y="total_bill", color="k", size=3, ax=g.ax)
# box plot과 swarm plot 결합
g = sns.catplot(data=tips, x="day", y="total_bill", kind="box")
sns.swarmplot(data=tips, x="day", y="total_bill", color="k", size=3, ax=g.ax)
범주형 추정도표 - bar plot
: 95% 신뢰구간을 자동으로 그려줌
# errorbar="sd" 으로 다른 방식으로 분산 표현 가능
sns.catplot(data=titanic, x="age", y="deck", errorbar="sd", kind="bar")

범주형 추정도표 - point plot
: 범주형 변수에 따라 다른 병수가 어떻게 변화하는지 나타냄.
점 추정치를 중심으로 95% 신뢰구간 표현
sns.catplot(data=titanic, x="sex", y="survived", hue="class", kind="point")
# marker, linestyle 옵션으로 선과 점 추정치의 형태 변경 가능
sns.catplot(
data=titanic, x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point"
)